Engineering Toil Reduction: How to Eliminate Repetitive Engineering Work


If your platform/DevOps team feels like a ticket queue, you’re paying the most expensive tax in engineering: toil.
Toil is the work that keeps production moving today but quietly prevents you from building systems that keep production stable tomorrow.
This article explains what toil is, how to measure it and a practical playbook to reduce it. Then we zoom in on the #1 modern toil factory in cloud teams: configuration drift and compliance drift.
Key points
- Engineering toil is operational work that’s manual, repetitive, automatable, tactical, and doesn’t create enduring value.
- Use DORA metrics to track the delivery impact (speed + stability).
- Drift (configuration + compliance) is a predictable, recurring source of toil—because reality always diverges from code and controls.
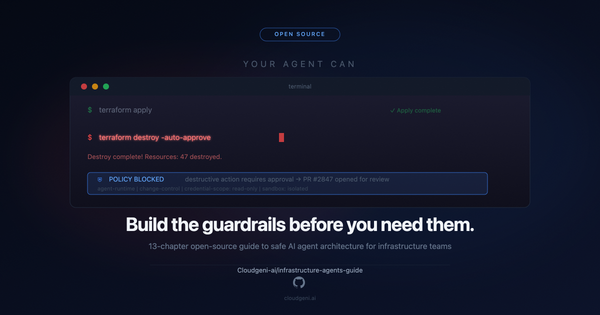
- Ready to reduce DevOps toil? Check out Cloudgeni to automate your infrastructure management process: detect → decide → PR → review → merge.
Definition: what is engineering toil?
Engineering toil is the work required to run a production service that tends to be manual, repetitive, automatable, tactical, and “devoid of enduring value,” and that scales linearly as your service grows.
Toil vs overhead vs investment
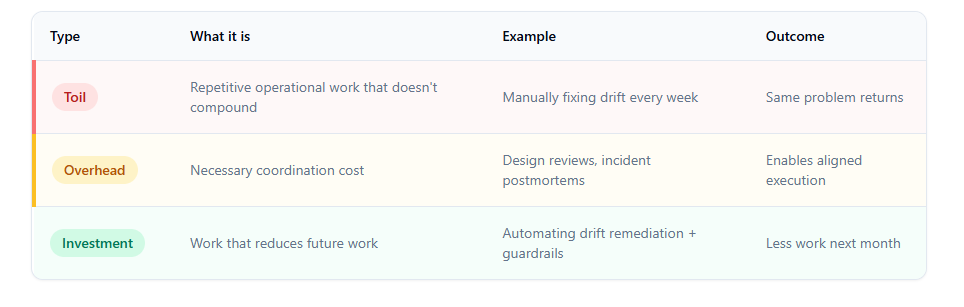
The goal isn’t “no ops.” The goal is: ops work that compounds.
Why toil reduction matters (in business terms)
Toil isn’t just annoying. It shows up as:
- Lower throughput: delivery depends on specific humans being available.
- Higher risk: manual steps create inconsistencies and mistakes.
- Worse reliability: teams stay reactive because they’re always in cleanup mode.
- Burnout: senior engineers spend time doing junior work.
It also blocks the flywheel you actually want: build automation → reduce incidents → free capacity → build more automation.
How to eliminate engineering toil: key steps
- Make toil visible before you try to fix it.
Toil is hard to remove when nobody can point to where it’s coming from. Start by tracking where time disappears: recurring tickets, interrupt-driven Slack work, manual production changes, and “someone needs to run this” moments. Then sanity-check against delivery signals. If lead time is creeping up or deployment frequency is flattening while interrupts rise, you’re not imagining it—your workflow is being shaped by toil. - Automate infrastructure management end-to-end, not just provisioning.
Many teams have IaC, but still burn time on drift, baseline enforcement, repeated fixes after incidents, and “temporary” exceptions that become permanent. Toil drops when infrastructure changes flow through versioned workflows (IaC + CI/CD) and when live state is continuously validated against what code and controls say should be true. In other words: stop treating drift as a surprise and start treating it as something the system should constantly reconcile. - Standardize tooling and add self-service with an IDP.
Standardizing how engineers get things done is one of the fastest ways to cut toil, because it removes the “everyone does it differently” tax. The most practical way to do this at scale is to build a self-service development platform often called an Internal Developer Platform (IDP). An IDP gives developers a set of approved actions they can run on demand without needing to understand (or manually execute) every underlying step. Instead of learning a fragile runbook or waiting for another team, developers follow prebuilt golden paths for common tasks like provisioning infrastructure, triggering builds, or accessing operational tooling. - Decentralize execution, centralize guardrails.
Central approval models create queues, and queues create toil. A scalable model lets teams execute changes in their scope while automated checks enforce safety. Low-risk changes should move quickly. High-risk changes should escalate with evidence and clear reasoning, not with meetings and back-and-forth. - Automate governance so security doesn’t become permanent work.
Security and compliance controls are necessary; manual enforcement is what turns them into constant toil. Move controls into the workflow with policy checks in CI, PR enforcement, and continuous scanning. This prevents non-compliant changes from reaching production and reduces the “audit scramble” dynamic that drains teams every quarter. - Fix the cultural leakage that keeps toil alive.
Even good tooling won’t help if teams bypass standards, keep one-off processes alive, or reward heroics over durable fixes. The practical goal is alignment: shared defaults, shared checks, and a bias toward turning repeated manual steps into automated, versioned workflows. That’s how you stop engineers from becoming human glue.
How Cloudgeni reduces toil: background agents that act like co-workers
Cloudgeni’s approach to toil reduction is blunt: stop turning drift into tickets.
Cloudgeni runs agents in the background that:
- Detect configuration drift and compliance drift
- Make decisions
- Generate the smallest safe patch
- Open a ready-to-review pull request
- Your team reviews and merges like any normal PR

That’s what “toil reduction” looks like when it’s real: humans stop doing repetitive remediation and start doing higher-leverage review and system improvement.
FAQ
What is engineering toil?
Operational work that is manual, repetitive, automatable, tactical, and doesn’t create enduring value (and scales with growth).
How do DORA metrics relate to toil?
Toil typically increases lead time, reduces deployment frequency, and worsens recovery time/change failure rate because more work becomes manual and interrupt-driven.
What is Terraform drift?
When real-world infrastructure state differs from what Terraform configuration (and state expectations) says it should be.
What’s the fastest way to reduce drift toil?
Turn drift fixes into PRs with evidence + rollback steps, and automate the decisioning for low-risk changes.