Configuration Drift: How to Detect It and Auto-Fix It Safely with PRs

Configuration drift is what happens when your actual cloud diverges from what your Infrastructure-as-Code (Terraform, OpenTofu, Pulumi, CloudFormation) says it should be.
If you think you “don’t really have drift,” the more likely truth is: you don’t measure it consistently, or you detect it but don’t close the loop.
Firefly’s 2025 research is blunt: only 8% report automated drift remediation, 40% say it takes days to weeks to fix drift, and 17% have no drift detection process at all.
What configuration drift looks like in real life
Drift is usually created by “reasonable” actions:
- An incident hotfix in the cloud console
- A temporary debug change that becomes permanent
- A script/agent modifying infra outside the IaC lifecycle
Terraform (and other IaC tools) will happily keep operating — until the drift shows up as a broken deploy, an unexpected replacement, a security regression, or a mystery cost spike. HashiCorp explicitly calls out downtime, breaches, and unnecessary costs as common consequences.
Why drift is getting worse (not better)
Two trends are amplifying drift:
- Multi-cloud + tool sprawl
- 68% of respondents operate across multiple clouds.
- “Consistency across environments” is a top pain point (56%), and only 13% say they’ve achieved IaC maturity.
- Automation everywhere (including AI)
Automation is now the default delivery pattern.
That’s good — but it also means more systems can mutate infrastructure. Drift becomes less about “someone clicked” and more about “something changed.”
Drift detection is solved enough. Drift remediation isn’t.
Most teams can detect drift. The failure mode is what happens next:
- Detection produces a finding…
- The finding becomes a ticket…
- The ticket becomes “we’ll handle it later”…
- “Later” becomes production damage.
So the real question is:
How do you fix drift fast - without breaking production - and without turning remediation into a second job?
That requires three things:
- Minimal, safe changes (avoid “fixing” by rewriting everything)
- Human-reviewable workflow (because auto-apply is how you create bigger incidents)
- Auditability (what changed, why, and how to roll back)
What the ecosystem offers today (and the hard limits)
1) Terraform / HCP Terraform drift detection
HashiCorp provides built-in drift detection in Terraform Cloud/HCP Terraform with continuous checks, drift visibility, and alerts.
This is strong for visibility — but it still leaves you with a decision: accept, revert, or codify the drift.
2) Cloud-provider compliance + remediation (fast, but can worsen IaC drift)
AWS Config supports remediation actions (including auto-remediation) using Systems Manager Automation documents.
AWS Systems Manager also supports diagnosing/remediating certain drifted configurations.
This is useful - but there’s a trap:
If the provider fixes the live resource but your code stays unchanged, you can end up with “drift in reverse”: IaC becomes the thing that’s wrong.
3) Open-source drift tooling (good diffs, you still own the fix)
driftctl is a popular open-source option to detect drift/unmanaged resources.
Its own docs recommend running continuously (scheduled) or integrating into GitOps workflows.
Again: detection is fine. Remediation remains manual.
4) Platforms that auto-remediate (powerful, but needs guardrails)
Tools like Spacelift describe scheduled drift scans and optional drift remediation runs, with the ability to review the plan before applying.
This is closer — but many teams still hesitate to let anything auto-apply changes to production.
That hesitation is rational.
The modern best practice: PR-first drift remediation
If you want speed and safety, the most defensible pattern is:
Treat drift like code: fix it with a pull request.
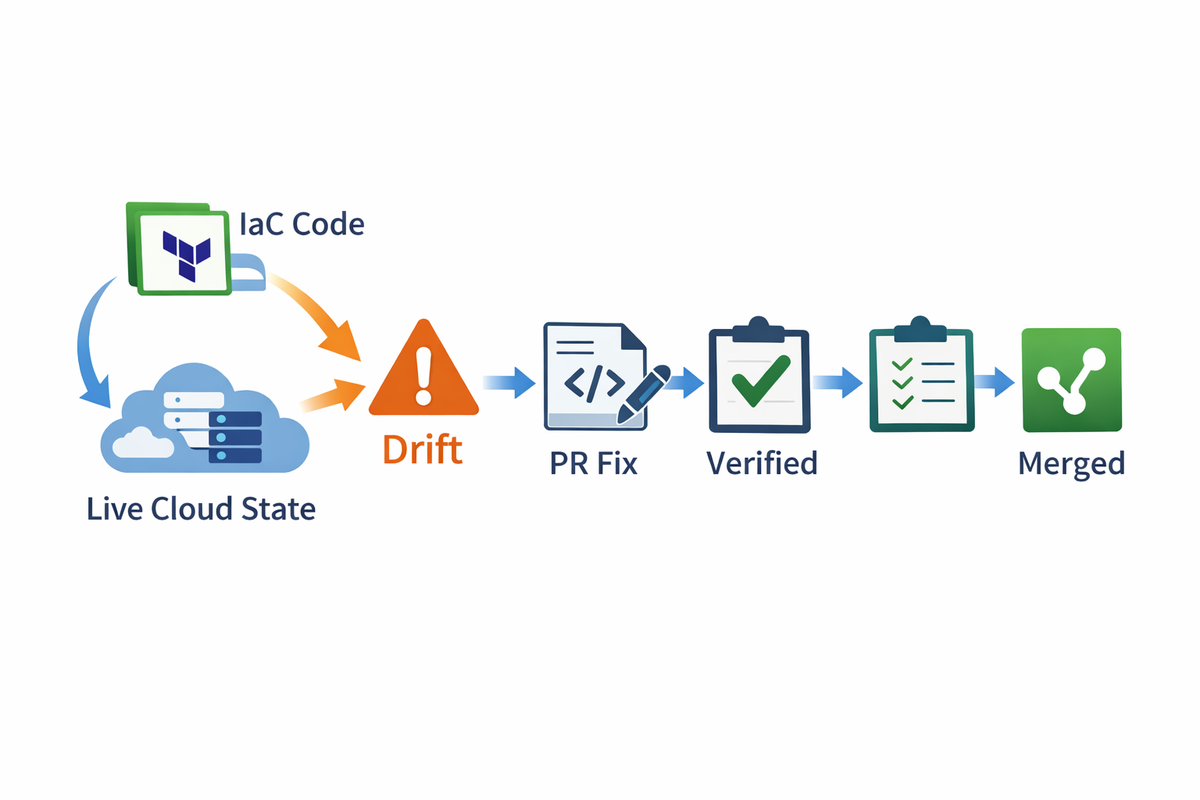
A PR-first remediation loop looks like this:
- Detect drift continuously
- Triage severity (security / reliability / cost / cosmetic)
- Generate the smallest safe code patch
- Open a PR with evidence + impact notes + rollback steps
- Run plan/tests in CI
- Human review + merge
- Apply via your normal pipeline
This gives you:
- Speed (automation does the heavy lifting)
- Control (humans approve what ships)
- Audit trail (Git history becomes your evidence)
How Cloudgeni changes the game: Drift remediation, not drift dashboards
Most products stop at “you have drift.” Cloudgeni is built around closing the loop.
Cloudgeni’s Drift Remediation Agent
What it does (in plain terms):
- Continuously compares live cloud state vs your IaC code
- Decides the minimal safe fix
- Opens a ready-to-review PR that restores alignment with context
Cloudgeni is opinionated about two things:
1) Fix drift by updating code (not just the live resource)
Provider-side remediation can be fast, but it can also create a mismatch where IaC becomes stale. Cloudgeni pushes toward Git as source of truth: fix drift by generating the IaC patch and letting your pipeline reconcile.
2) Deterministic, policy-bound changes
Infrastructure is not the place for “close enough.” Cloudgeni’s approach is deterministic-by-design: if it can’t generate a safe fix that matches your structure and guardrails, it stops instead of guessing (the exact behavior you want in production).
What a “good” drift-fix PR includes
A drift PR should answer, immediately:
- What changed in the cloud?
- Why is it risky / costly / breaking?
- What will the fix do?
- What’s the rollback?
- What evidence proves the drift existed?
HashiCorp highlights drift visibility and attribute-level change visualization as key context.
Cloudgeni’s PR-first workflow makes that context reviewable where engineers already work: the PR.
A practical drift remediation playbook
Step 1: Classify drift into 3 buckets
- Revert drift (unsafe or unauthorized change)
- Codify drift (the live change is correct; code is behind)
- Ignore drift (ephemeral/noise — but document why)
Step 2: Add “risk gates” before any automation
Auto-remediation should be gated by:
- Blast radius (prod vs non-prod)
- Resource type sensitivity (IAM, SGs, KMS, network routing)
- Change type (additive tag change vs destructive replacement)
- Confidence (can you prove no downtime impact?)
Step 3: Track the only drift metrics that matter
- Drift MTTR (time from drift introduced → merged fix)
- Drift recurrence rate (same drift coming back)
- % infra changes through PRs (console change leakage)
- # unmanaged resources (shadow infrastructure)
FAQ
What is configuration drift?
Configuration drift is the gap between the desired configuration (IaC definitions) and the actual live state in the cloud, usually caused by out-of-band changes, automation, or failed deployments.
How do I detect drift in Terraform?
Common approaches include running terraform plan on a schedule, using HCP Terraform/Terraform Cloud drift detection, and using drift tooling like driftctl for continuous monitoring.
Why is drift remediation harder than drift detection?
Detection tells you “something changed.” Remediation requires deciding whether to revert or codify, generating the correct patch, proving safety, and rolling it out without downtime.
Can AWS auto-remediate drift?
AWS Config supports remediation (including auto remediation) using Systems Manager Automation documents, but it typically changes live resources which can leave IaC out of sync unless you also update the code.
What’s the safest way to auto-fix drift?
PR-first remediation: generate a minimal IaC patch, open a pull request with evidence/impact/rollback, run CI checks, and require human approval before apply.